
Come see us at Mobile World Congress Americas (MWCA) in San Francisco, where you can don our VR headset to experience the world of big data.
You’ve heard of big data...but have you ever actually seen it? Now you can, at our VR showcase taking place at MWCA. We are opening up our virtual reality “big data space” to the public at MWCA, to help everyone better understand how we use big data to protect over 400 million users worldwide.
Those same hundreds of millions of users actually double as information sources that feed our big data. If anything malicious or questionable tries to infiltrate a user’s system, we immediately know about it. Our AI-based machine learning network processes the info, analyzing the potential danger, then takes the necessary steps to fortify against it.
Another way our big data helps is by contributing to our enormous “reputation database.” If you access a URL or run a new program, the reputation database tells us how many users have accessed those same items. Mainstream, safe programs and websites would be frequently accessed, so if we see that only a scant amount of users have accessed them, we know they may not be what they say they are.
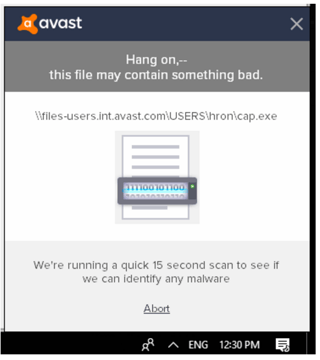
If you get the above message, it indicates that we have cordoned off a suspicious file with our CyberCapture program. In essence, we are taking that file and running it in an isolated sandbox environment. If CyberCapture does this and verifies the file is safe, you are free to access it. If, however, CyberCapture decides it needs more analysis, the file is sent to our Threat Lab for further inspection.
To dig deeper into the nature of the files, we extract a sample, which we call a “feature vector.” It’s a cross-section of the most important characteristics of the file. We feed this information into our machine learning system, which compares it to all of our big data, and ultimately categorizes it as clean, malicious, or a “potentially unwanted program” (PUP). The more big data we collect, the easier it gets to compare questionable files and programs to other known entities.
We encounter millions of files a day, so we have amassed an extraordinarily large database. We currently have roughly 330 TiB of data—a virtual “galaxy” of programs, which explains why our VR representation feels somewhat like a space walk. Our data analysts step into that virtual world to better and more quickly inspect our machine learning process and verify the proper classification. Ultimately, this balance of machine learning and AI along with guidance from our threat analysts allows Avast to protect against emerging and known threats—this is next-gen cybersecurity.
Visit the Avast booth at N.658 in the North Hall Moscone Center. Put on the VR glasses and experience a virtual universe of malware, and learn how Avast uses AI and Machine Learning to protect over 400 million users. See you there!
1988 - 2026 Copyright © Avast Software s.r.o. | Sitemap Privacy policy