
Scrapers may have easier access to your account info than you're aware of
Last month, a massive data leak exposed more than 300 million different accounts from social media platforms. The collection included 192 million records scraped from two different Instagram collections, along with 42 million records scraped from TikTok and an additional 4 million records scraped from YouTube.
The records include usernames, profile photos, emails, phone numbers, age and gender along with specifics about followers and other engagement for each account. The leak involved a set of three open data shares from the company Social Data: a few hours after being notified, the shares were properly secured.
There are several things that are interesting about this leak: its source, how the data was obtained, and what this means for your own social media consumption.
Further reading:
Social Data is based in Hong Kong and was created after the demise of another company called Deep Social. The latter company appears to be the original collector of the leaked data. Both companies provide demographic and psychographic data of social media influencers to major consumer brands. Deep Social was shut down in 2018 after Facebook reportedly banned it from using its marketing data interfaces and threatened legal action. Social Data began its operations in 2019. There are plenty of other “influencer marketing” agencies who sell this kind of data, in case you're interested in learning more about this corner of the internet universe.
As we all well know, users don’t pay to support social media platforms -- they make money selling advertising. To be effective, the platforms must track who accesses particular content and the platforms all have various computer interfaces to enable advertisers to target where their ads appear based on this activity.
But these interfaces can also be abused, and that was the problem with what Deep Social did. There are two ways that these agencies can operate: One is by playing by the rules and obtaining the user data the way Facebook and others have intended. The other is by scraping the data directly off each account’s webpage and hope the social media companies don’t detect it.
Web scraping has been going on almost since the web was first invented in the early 1990s. Chances are good that someone has copied your web content and is hosting it as their own elsewhere online. What has happened is that the automated scraping tools have gotten better at avoiding detection. Cloudflare has a more technical explanation here about the operations of these “scraper bots” as they are called.
However, the bots aren’t perfect, and people do get caught. The most prominent example is Clearview.ai, which scraped users’ images and then mass-marketed its face recognition technology. Another case happened in 2014 with LinkedIn, where someone scraped thousands of personal profiles and then used them in a site that was created for their own recruiting purposes.
What kind of content is available to the scrapers? Here is a screenshot from Comparitech that illustrates the level of detailed information from one user’s Instagram account.
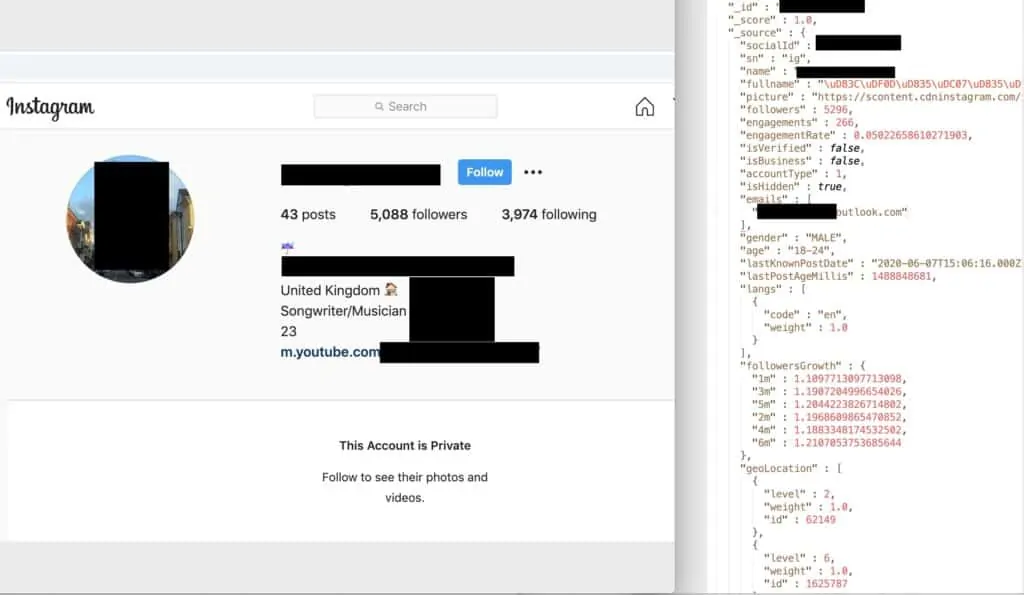
Credit: Comparitech
There are ways to defend against the scrapers, depending on whether it is business or personal content you are trying to protect. There are various tools that can help businesses detect when their web content has been lifted and reused elsewhere, including from Cloudflare and Imperva. But these are beyond the reach for personal purposes, and that means you must be more vigilant about what and how you post your photos, videos, and pithy thoughts online. You should think about the following:
1988 - 2026 Copyright © Avast Software s.r.o. | Sitemap Privacy policy