
The evolution of Avast Evo-Gen: Using machine learning to protect hundreds of millions of users
As one of the leading companies in computer security, we work hard every day to bring the highest level of protection to all of our users. This requires us to constantly explore new ways of defeating malware, often experimenting with bleeding edge technology or approaches that have never been tried in our environment before - borrowing ideas from fields like biology or physics. Many of these experiments never deliver anything substantial but sometimes the results exceed even our most optimistic expectations. Here, I would like to talk about one such experiment. We started it over six years ago and it evolved into a system that quickly became one of the strongest malware detection engines we use at Avast today.
The system is called Evo-Gen and if you read our blog closely you might have heard about it in a blog post by our CTO Ondřej Vlček. Back in 2012, we were in the process of deploying this new system for all Avast users for the first time. While we haven’t been really covering it anymore on our blog, we have been hard at work for the past five and half years constantly monitoring and improving it. If this is the first time you hear about Evo-Gen or you simply don’t remember what it is, let me briefly describe it for you:
Evo-Gen is a machine learning system used to classify unknown samples in real-time. For samples recognized as malicious, it quickly creates a definition that is immediately streamed to all Avast users to protect them against the new threat.
The definitions it creates (called “evogens”) are very small and simple in nature, which means they are very easily evaluated. Moreover, every evogen usually protects against more than just one threat - these definitions are made to be generic so that they cover more than one variant of a given threat.
Since its deployment to production in early 2013, Evo-Gen has created more than 1.2 million such definitions that identify almost 500 million unique malware samples. If you do the math that means every day over 600 evogens are created and each identifies over 400 samples on average! The datasets that it uses for every decision have also grown considerably – from a few million to over a hundred million unique samples and that is not taking into account the hundreds of millions more that we use for offline analysis and threat intelligence. The biggest growth was thanks to the acquisition of AVG which enriched the datasets with tens of millions of new samples.
The system is fully automated – no human interaction is required. It is constantly hard at work analyzing incoming samples and comparing them against a huge collection of samples gathered over the years. All definitions that it produces are almost instantly sent to all Avast users using our Streaming Update technology thus providing them with high quality protection in a timely manner.
In rare cases, there is a mistake and a released definition has to be disabled. But when that happens, the system learns from it and won’t make the same mistake again. Out of all the evogens it created so far more than 40% are still active and used every day. A few of these are true record holders – identifying not hundreds but millions of unique samples.
As I have mentioned at the beginning of this post, the whole system went through a lot of changes since its deployment in early 2013. It evolved from a small proof of concept with short-lived definitions to a high quality and stable malware detection engine. This is most evident on the aggregated graph below where you can see that in the past we had to disable a lot more evogens than today:
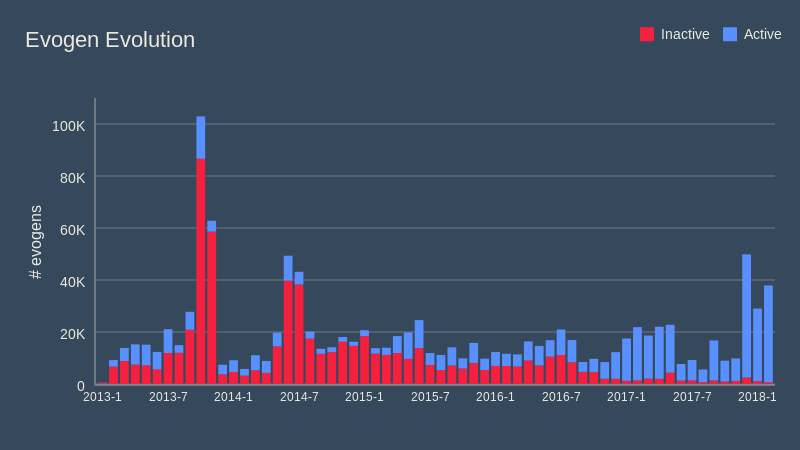
You might notice the large spike in number of definitions created in summer 2013. At that time we wanted Evo-Gen to produce more generic definitions in order to cover a broader range of threats. Because of this, we increased the amount of randomness the definition generator was allowed to use. However a few months later this change had to be reverted because it proved to be too aggressive, so we went back to a more deterministic approach. It was interesting to see how in our internal tests we did not experience any problems with adding more randomness but the incredible variety of samples from the outside world caused our system to produce too many definitions with corner case false positives. Discovering this problem in a lab environment was simply not possible and we had to learn our lesson the hard way.
During 2014, we focused mostly on stabilizing the system – fixing bugs and taking care of corner cases here and there. Then, in 2015, we began talking about a major rewrite of the generator algorithm. So far our approach did not really leverage the full capabilities of the underlying database system – namely the similarity search which was used very naively to perform a k-NN search with some domain specific constraints and expert knowledge rules. After some research, we concluded that using HDBSCAN (a variant of https://en.wikipedia.org/wiki/DBSCAN ) was the best fit and our preliminary tests showed it to be promising. However developing a variant that performed well under the time constraints we had (remember the system is supposed to create a definition in real-time!) proved to be quite a challenge so it took more than a year to deploy it to production. That happened in late 2016 and was an absolute success. Just a few months after deployment we saw a dramatic decrease in the number of disabled evogens either due to internal or external false positives. In 2017, we made a few minor tweaks to the algorithm and improved the performance of the underlying databases which boosted its performance even further.
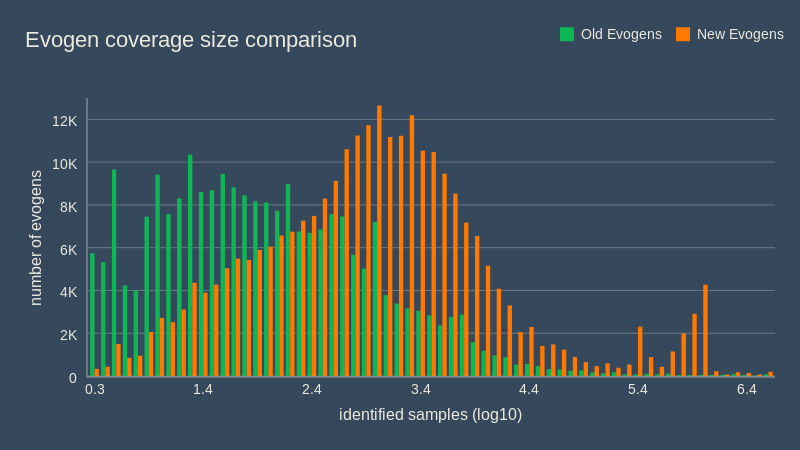
The chart below nicely compares the old and new definition generator with respect to definition sample coverage (the amount of unique samples each definition is able to identify). You can see that the old version generated evogens with smaller coverage than the new one. Combined with the much lower rate of disabled evogens, we saw a considerable increase in detected samples. Evo-Gen was becoming one of the strongest detection engines beating legacy systems in both quality and speed.
But we are not going to stop here. Let us first look at what makes Evo-Gen so powerful:
The above traits are what makes machine learning so useful. It is also much easier to scale than a team of humans since you can easily buy a couple more servers but hiring several skilled malware analysts is quite difficult.
However, there is one drawback. Since threats must be neutralized before they are fully understood and mapped, individual evogens cannot be fine tuned to perfection because they have to be released as soon as possible. This ultimately leads to the system creating several evogens for one malware family and in some cases even hundreds of them. The graph below illustrates how the redundancy happens:
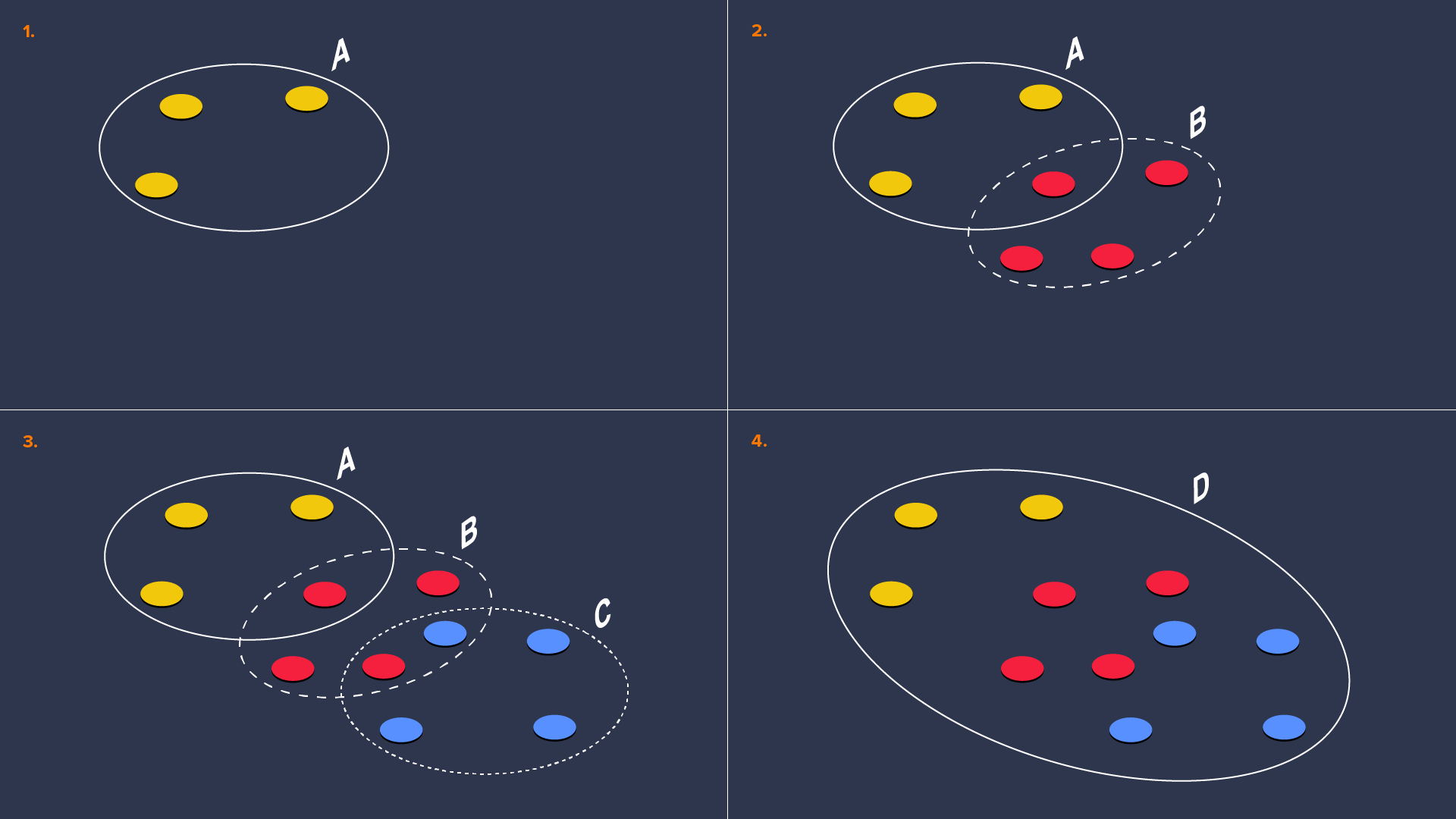
In the first image above, we see three yellow circles representing a few variants (samples) of one malware family. They are contained inside a grey ring which represents one definition (evogen A) that is capable of identifying them. However later more variants (red) emerge and while some are still identified by evogen A there remain others that are not. Thus evogen B is created to take care of them. This repeats in the third image with blue variants and evogen C. The last image shows the ideal situation where one definition (evogen D) is capable of taking care of all the variants.
If one had all the samples beforehand it would certainly be possible to create just one or a few evogens that would cover them all. This would make scanning for threats easier – the less definitions there are, the less time it takes, and the smaller the updates must be. Unfortunately this is not possible in practice since it requires waiting for more samples, allowing the first few to spread. And that is not acceptable for us. Thankfully this redundancy can be solved later - by tackling a well know problem known as “set cover problem”. In this problem, one has a set of elements (in our case the malware samples) and a collection of sets (evogens) whose union equals all the elements. The goal is to identify the smallest sub-collection of sets (evogens) whose union still equals all the elements. This is a NP-complete problem but fortunately for us we don’t need the perfect solution, just a good enough one. We have built a tool that does exactly that and, after feeding it with all the data (over half a million of evogens and nearly 500 million samples), we were rewarded with the following result:
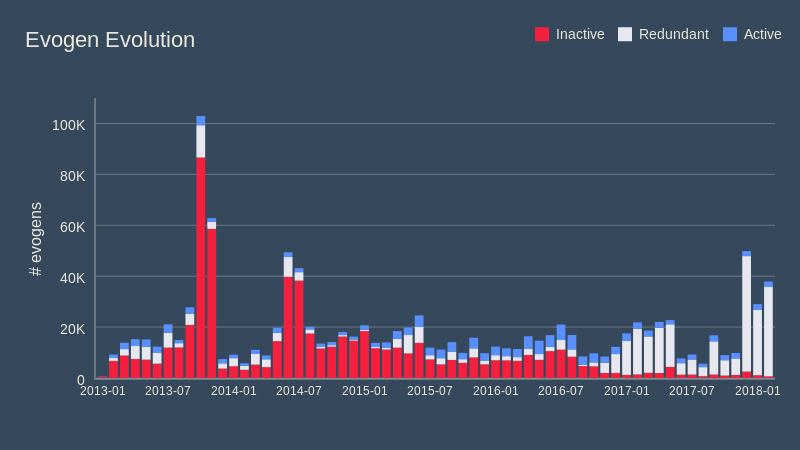
Almost 60% of evogens were flagged as redundant which means we can safely remove them resulting in a massive optimization! Of course, in practice, we will be a bit more conservative just to be safe, but this shows us that we can reduce the number of definitions significantly without impacting our protection capabilities in any way. Fewer definitions means faster scans and smaller updates so it’s a win for the user too.
One thing you might notice is that redundancy seems to be happening more recently, but that is only partly true. The redundancy was always there but previously we had more bad evogens so many redundant evogens have already been disabled and are “hidden” (part of the red bar). Additionally, the new algorithm deployed in late 2016 is much better at predicting the true threat cluster, but it looks at the threat from many different angles (depending on the specific sample it analyzes) which leads to overlapping but correct evogens. The older algorithm did not have this feature because it was either a bit too random or too deterministic.
At Avast, we are committed to keeping our users safe online and we’re always looking for new ways to protect them. Evo-gen is one good example of a technology that took a long time to develop, but which definitely paid off, helping to increase the level of protection we can offer our users. We are always investigating and looking for new opportunities that keep Avast and our users protected in the ever-changing world of malware threats.
1988 - 2026 Copyright © Avast Software s.r.o. | Sitemap Privacy policy