
Another nasty trick in malicious PDF
A new method of producing malicious PDF files has been discovered by the avast! Virus Lab team. The new method is more than a specific, patchable vulnerability; it is a trick that enables the makers of malicious PDF files to slide them past almost all AV scanners.
Overall, PDF specifications allow many different filters (such as ASCII85Decode, RunLengthDecode, ASCIIHexDecode, FlateDecode, …) to be used on raw data. In addition, there is no limit on the number of the filters used for a single data entry. Anyone can create valid PDF files where the data uses, for example, five different filters or five layers of the same filter. All of these features are based on extremely liberal specifications, a fact which allows bad guys to utilize malicious files in a way that does not allow antivirus scanners access to the real payload.
The new trick is based just on one filter, so it doesn’t sound exciting, does it? So what’s the reason for posting this blog post?
The filter used to encrypt text data is meant to be used only for black and white images. And apart from avast!, probably no other AV scanner is currently able to decode the payload because no other AV can detect those PDF files.
This story began when we found a new, previously unseen, PDF file a month ago. It wasn’t detected by us or by any other AV company. But its originating URL address was quite suspicious and soon we confirmed the exploitation and system infection caused by just opening this document. But our parser was unable to get any suitable content that we could define as malicious. There wasn’t any javascript stream, just the single XFA array shown in the next image.

XFA forms usually contain a malicious TIFF image that exploits the well-known CVE-2010-0188 vulnerability. We were interested in the objects referenced by the XFA array. As you can see, there were just two references:
The dataset object was easy to decode by our scanner as it uses one extremely common filter – FlateDecode. The data decoded from the stream wasn’t suspicious anyway - just some data encoded with the base64 algorithm (as shown in next image). The main payload had to be covered by the first - template object.

Unfortunately, our scanner wasn’t able to decode this content. So what was wrong? Why were other AV engines also unable to detect such an exploit? The answer to those questions is shown in the next image.

The image above is the object stream definition. It says that the object is 3125 bytes long and that we must use 2 filters to decode the original data – FlateDecode as first layer and JBIG2Decode as a second layer. But why JBIG2Decode? That’s a pure image encoding algorithm isn’t it? Correct, and following text is what Adobe says about it in the PDF documentation (Part 3.3.6, page 80):
The JBIG2Decode filter (PDF 1.4) decodes monochrome (1 bit per pixel) image data that has been encoded using JBIG2 encoding. JBIG stands for the Joint Bi-Level Image Experts Group, a group within the International Organization for Standardization (ISO) that developed the format. JBIG2 is the second version of a standard originally released as JBIG1.
JBIG2 encoding, which provides for both lossy and lossless compression, is useful only for monochrome images, not for color images, grayscale images, or general data. The algorithms used by the encoder, and the details of the format, are not described here. A working draft of the JBIG2 specification can be found through the Web site for the JBIG and JPEG (Joint Photographic Experts Group) committees at < http://www.jpeg.org >.
And following text that is taken from the same specification (Part 4.8.6, page 353):
Also note that JBIG2Decode and JPXDecode are not listed in Table 4.44 because those filters can be applied only to image XObjects.
That’s another surprise from PDF, another surprise from Adobe, of course. Who would have thought that a pure image algorithm might be used as a standard filter on any object stream you want? And that’s the reason why our scanner wasn’t successful in decoding the original content – we hadn’t expected such behavior. To be fair, any data (text or binary) can be declared as an monochrome two-dimensional image – that’s the reason why JBIG2 algorithm works here.
We guessed that the image would probably has its first dimension set to 1 pixel and the second would be set to a much higher number of pixels. That’s the easiest way how to declare non-image data as a monochrome picture. The following picture shows the data processed by the FlateDecode filter, so it’s actually a JBIG2 stream (PDF version of JBIG2, as the file header is missing here).

Two colored 32bit numbers on the picture above represents the image dimensions. You can see that our guesses were right. Image is 25056 (red: 0x000061E0) pixels wide and just 1 pixel (yellow: 0x00000001) high. Remember that the image is monochrome so 1 pixel = 1 bit. To get the size of the decoded data in bytes, we need to divide the width by 8 and get 3132 bytes. The following image shows real content after two decoding procedures.

The content is the well-known as CVE-2010-0188 exploit. The bad guys are building a specially-crafted TIFF (see underlined text in the image, that’s a TIFF header encoded by base64 algorithm) file which exploits Adobe Reader. The vulnerability is patched in current versions, only old versions are affected.
We released PDF:ContEx [Susp] detection immediately after this discovery. We have been monitoring this new trick now for over a month and now added this decoding algorithm to our PDF engine. Based on the information from the avast! Virus Lab logs, this new trick is currently used in only a very small number of attacks (in comparison to other attacks) and that is probably the reason why no one else is able to detect it. However, we have seen this nasty trick also being used in a targeted attacks.
Here are the links to VirusTotal showing the detection score:
In addition, we have found another 10 malicious PDF files based on the JBIG2Decode trick. All of them were actually detected using our heuristic detection JS:Pdfka-gen even if we did not actually decode the JBIG2 streams. In these cases, different objects (objects without a JBIG2Decode filter) have been marked as malicious parts. In summary, we can say that bad guys are using this trick to hide any possible object they want to be hidden (XFA forms, JS, TTF).
The following image shows an object which is encoded using the JBIG2Decode filter, but this time the object contains specially crafted font (TTF) file which exploits CVE-2010-2883 vulnerability.
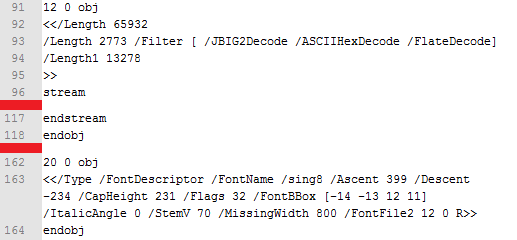
The image above contains only two (the source PDF contains many more) objects. Object 12 (line 91 in the image) contains encoded data. After we decoded the content using all three filters (JBIG2Decode, ASCIIHexDecode, and FlateDecode) we got the malicious font file. But this object defined only the raw data, there had to be another object that defined the font itself and that’s the second object shown in the image – object 20 (line 162). This is the FontDescriptor which is used to specify the metrics and other parameters of custom embedded fonts. In this case, last parameter is the key to malicious font file - /FontFile2 12 0 R, a reference to the previously defined object.
Here is the link to VirusTotal showing the detection score:
I’m not happy to see another trick based on a glitch in the PDF specification. What should we expect to happen next?
For more goodies, come attend our talk in Prague at the CARO 2011 Workshop. (link)
1988 - 2024 Copyright © Avast Software s.r.o. | Sitemap Privacy policy