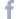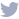アバスト Evo-Gen の進化:機械学習を利用して何百万人ものユーザーを保護するために
はじめに
アバストは、コンピューター セキュリティ分野のリーディングカンパニーとして、すべてのユーザーに最高レベルの保護を提供するために日々、努力しています。そのため、最先端の技術や、生物や物理など他の分野からヒントを得た斬新なアプローチを試しながら、マルウェアに対抗する新しい手段を常に模索しています。これらの実験の多くは、期待するような結果が出ないものです。しかし時には、私たちの最も楽観的な予測さえ超える結果が得られることもあります。今回は、そのような実験のひとつについてお話します。実験を開始したのは 6 年以上前ですが、その結果、現在アバストで使用している最強のマルウェア検出エンジンが誕生しました。
そのシステムの名前は Evo-Gen です。アバストのブログの熱心な読者なら、当社の CTO である Ondřej Vlček が執筆したブログ記事で、この名前を目にしたことがあるかもしれません。2012 年当時、私たちはこの新しいシステムを初めてアバストの全ユーザーに導入するプロセスの最中でした。その後、ブログ記事ではほとんど紹介していませんでしたが、この 5 年半の間、私たちは Evo-Gen のモニタリングや改善に取り組み続けてきました。Evo-Gen という名前を初めて見る方や、見たことはあってもどんなものか覚えていない方のために、簡単にご説明しましょう。
Evo-Gen は、未知のサンプルをリアルタイムで分類するための機械学習システムです。サンプルが悪意のあるものとして認識されると、瞬時に定義を作成してアバスト ユーザー全員に配信し、新しい脅威から保護します。
作成される定義(「evogen」と呼ばれます)は、非常に小さく単純なため、簡単に評価できます。さらに、それぞれの evogen は通常、複数の脅威に対する保護を提供します。汎用的に作成されているため、特定の脅威の複数の変種に対応できるのです。
数字で見る Evo-Gen
2013 年の初めに実稼働環境に導入して以来、Evo-Gen は 120 万以上の定義を作成し、5 億近い固有のマルウェア サンプルを識別してきました。毎日、平均 600 以上の evogen が作成され、それぞれが 400 以上のサンプルを識別している計算になります。また、識別に使用するデータセットも大幅に拡大し、固有サンプル数は数百万から 1 億以上に増えました。これには、私たちがオフライン分析や脅威インテリジェンスに使用する数億ものサンプルは含まれていません。サンプル数の増加に最も寄与したのは、AVG の買収です。買収により、データセットに何千万もの新しいサンプルが加わりました。
このシステムは完全に自動化されていて、人による操作はまったく必要ありません。入ってくるサンプルを休むことなく分析し、何年もかけて蓄積された膨大なサンプルと比較します。作成された定義はすべて、アバストのストリーミング アップデート技術を利用してほぼ瞬時に全ユーザーに送信されるため、タイムリーに高度な保護を提供できるようになります。
ごくまれに、何らかのミスが発生して、送信済みの定義を無効化する必要が生じることがあります。その場合にも、システムがそこから学習するため、同じミスが繰り返されることはありません。これまでに作成された全 evogen のうち、4 割以上は現在も有効で、毎日使用されています。その中には、数百ではなく、数百万単位の固有のサンプルを識別した実績を持つものもいくつかあります。
Evo-Gen の進化
この記事の冒頭で述べたように、2013 年初めに導入が開始されてから、Evo-Gen はさまざまな変化を遂げてきました。最初は小さなプロトタイプで、作成する定義は短命なものばかりでしたが、今や高品質で安定したマルウェア検出エンジンへと進化しました。次の集計グラフを見ると、以前は今よりもはるかに多くの evogen を無効化する必要があったことがよくわかります。
また、2013 年の夏に、定義の作成数が急増しています。私たちは当時、さらに幅広い脅威に対応するため、Evo-Gen が作成する定義の汎用性を高めようと考えていました。そのため、定義生成プログラムが使用できるランダム性の程度を増やすことにしました。ところが、この変更は過剰な結果をもたらすことが判明し、数か月後には、より決定論的なアプローチに戻すことになりました。興味深いことに、内部テストの段階では、ランダム性を増やしても問題は起きなかったにもかかわらず、外部から多種多様なサンプルが入ってくると、特殊なケースにおいて誤検出をする定義が多く作成されるようになりました。研究所内で実験しているだけでは、この問題を発見することは不可能でした。私たちは身をもってそれを学んだのです。
2014 年は、主にシステムの安定化に重点を置き、バグの修正や特殊なケースの対処に取り組みました。そして 2015 年には、定義生成アルゴリズムの大幅な改訂を検討し始めました。それまでの私たちのアプローチは、ベースとなるデータベース システムの機能をフルに活用できていませんでした。具体的には、ドメインに特化した制約と専門家の知識ベースのルールを用いた k-NN(k 近傍)検索を単純に類似検索で行っていました。調査を行った結果、HDBSCAN(https://en.wikipedia.org/wiki/DBSCAN の変種)を使用することが最適だという結論に至りました。予備的な検証を行った際の結果も、期待がもてるものでした。しかし、定義をリアルタイムで作成しなくてはならないという時間的な制約の中で効力を発揮できる変種を開発するのは非常に難しく、実稼働環境に導入するまでには 1 年以上かかかりました。2016 年後半にようやく完成した新しいアルゴリズムは大成功でした。導入からわずか数か月後には、内部あるいは外部での誤検出を理由に無効化された evogen の数が劇的に減りました。2017 年には、アルゴリズムの微調整を行い、ベースとなるデータベースの性能を向上させました。その結果、Evo-Gen の性能はさらに上がりました。
次のグラフは、定義のサンプル カバー率(各定義が識別できる固有サンプル量)という点から新旧の定義生成プログラムを比較したものです。古いバージョンで生成された evogen のカバー率が、新しいバージョンと比較して低いのがわかります。新バージョンでは、無効化された evogen の割合がはるかに少ないことも加味すると、検出されるサンプル量が大幅に増えたことになります。新しいアルゴリズムの導入により、Evo-Gen は、質、速度共にレガシー システムを超える最強の検出エンジンになりつつありました。
さらなる改善に向けて
Evo-Gen の進化は、これからも続きます。その前に、Evo-Gen がなぜ強力なのかをまとめてみましょう。
上記の特徴はいずれも、機能学習がいかに効果的かを示すものです。また Evo-Gen は、人間のチームよりも、はるかに簡単に規模を拡大できます。サーバーを数台購入するのは簡単ですが、熟練したマルウェア アナリストを数人雇うのは非常に難しいことです。
とは言え、ひとつだけ欠点があります。脅威を完全に理解し、マッピングするには、まず無力化する必要がありますが、evogen は、なるべく早く配信する必要があるため、個々を完璧に調整するのは不可能です。その結果、1 つのマルウェア ファミリーに対して、複数の evogen を作成することになります。その数が数百に及ぶケースもあります。次のグラフは、重複がどのように発生するかを示すものです。
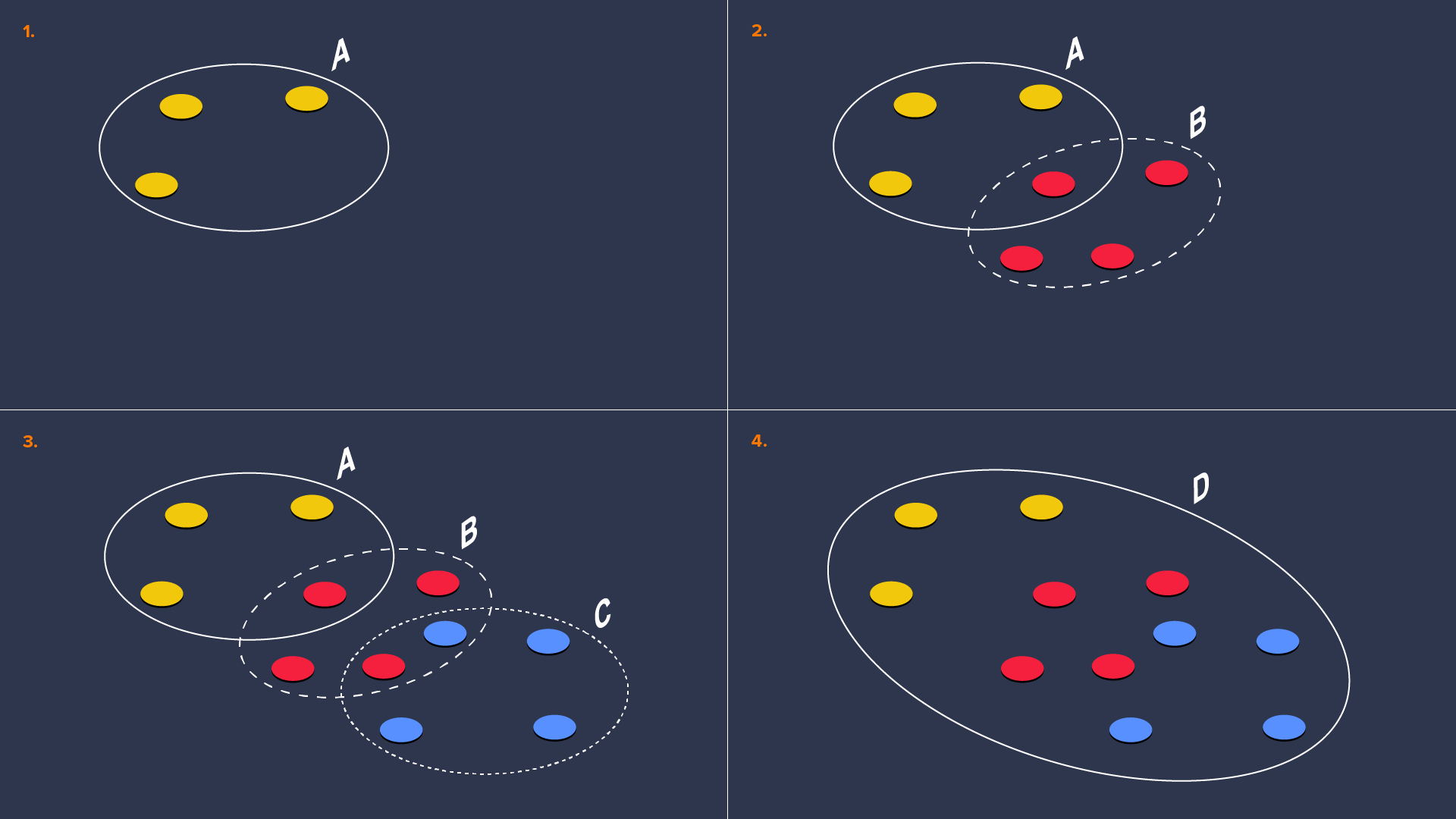
1 番目の図は、3 つの黄色い丸によって、1 つのマルウェア ファミリーの変種(サンプル)をいくつか表しています。黄色い丸は、それらを識別できる 1 つの定義(evogen A)を表す灰色の円に囲まれています。その後、新たな変種(赤)が出現しますが、evogen A によって識別できるものもあれば、識別できないものもあります。識別できない変種に対応するために、evogen B が作成されます。さらに 3 番目の図で、青い変種と evogen C で同じことが繰り返されます。最後の図は、1 つの定義(evogen D)によって、すべての変種に対応できるという理想的な状況を示しています。
事前にあらゆるサンプルが手元にあれば、すべてに対応できる evogen を 1 つまたは数個だけ作成することが当然可能になります。そうすれば、より簡単に脅威をスキャンできます。定義の数が少なければ、その分スキャンの時間が短くなり、小さなアップデートで済みます。残念ながら、実際にそうすることは不可能です。サンプルがさらに出現し、最初の数個が拡散されるのを待つ必要があるからです。しかし、私たちとしては待っているわけにはいきません。幸いなことに、定義の重複は後に「集合被覆問題」というよく知られた問題を解くことで解決できました。この問題では、要素の集合(この場合は、マルウェアのサンプル)と、和集合が集合の全要素と等しい集合の族(evogen)が与えられています。部分集合の族(evogen)から、和集合が集合の全要素に等しくなる最小の部分集合を特定するのが目標です。この問題は NP 完全な問題ですが、幸い私たちの目的は、完全な解答ではなく「十分な」解答を得ることです。その目的を果たすためのツールを作り、すべてのデータ(50 万以上の evogen と 5 億近くのサンプル)を投入したところ、次のような良い結果が得られました。
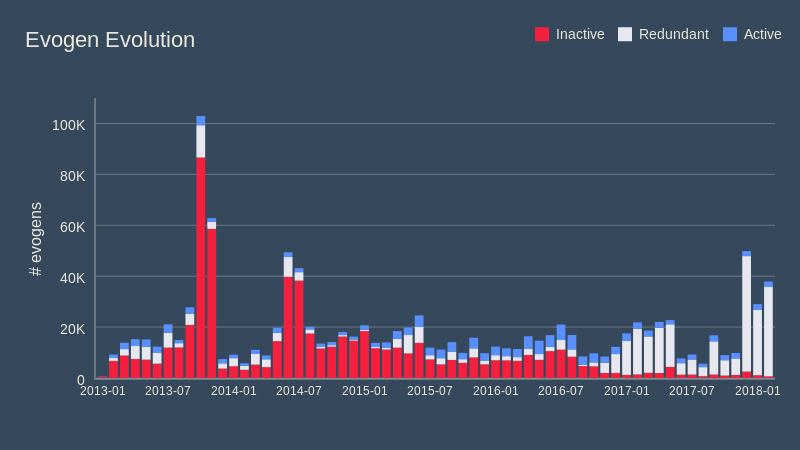
6 割近い evogen が重複していると認識されました。つまり、それらを削除しても問題はなく、大幅な最適化につながるということです。もちろん実際には、念のためもう少し慎重になる必要がありますが、保護機能に一切影響を与えることなく、定義の数を大幅に減らすことが可能であることが証明できました。定義数が少なければスキャンの時間が短くなり、小さなアップデートで済むため、ユーザーにとっても大きなメリットになります。
グラフを見ると、重複している定義の数が最近増えている印象を受けるかもしれませんが、実態は少し違います。重複は以前から存在していましたが、以前は誤検出をする evogen が今よりも多かったため、すでに多くの重複 evogen が無効化されていて数字に含まれていないのです(赤い棒に含まれています)。また、2016 年後半に導入した新しいアルゴリズムは、真の脅威クラスターを予測する能力には優れているものの、(分析するサンプルによって)脅威をさまざまな角度からとらえるため、正しい evogen が重複する原因となっています。以前のアルゴリズムには、ランダムすぎる、または決定論的すぎるという理由で、この機能は含まれていませんでした。
結論
アバストの使命は、ユーザーのオンライン セキュリティを確保することです。私たちは、ユーザーを保護するための新しい方法を常に模索しています。Evo-gen の開発には時間がかかりましたが、そのかいあって、ユーザーに提供する保護レベルの向上に貢献する技術となりました。 変化し続けるマルウェアの脅威から自社とユーザーを守るために、アバストはこれからも新たな機会を探し求めていきます。
1988 - 2026 Copyright © Avast Software s.r.o. | Sitemap プライバシーに関する方針