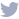Los "scrapers" pueden tener un acceso más fácil a la información de tu cuenta más de lo que tú sabes
El mes pasado, una filtración masiva de datos (sitio en inglés) expuso más de 300 millones de cuentas diferentes de plataformas de redes sociales. La colección incluyó 192 millones de registros extraídos de dos colecciones de Instagram diferentes, junto con 42 millones de registros extraídos de TikTok y 4 millones de registros adicionales extraídos de YouTube.
Los registros incluyen nombres de usuario, fotos de perfil, correos electrónicos, números de teléfono, edad y sexo, junto con detalles sobre los seguidores y otras interacciones de cada cuenta. La filtración involucró un conjunto de tres acciones de datos abiertos de la empresa Social Data: unas horas después de recibir la notificación, las acciones estaban debidamente aseguradas.
Hay varias cosas que son interesantes sobre esta filtración: su fuente, cómo se obtuvieron los datos y qué significa esto para el propio consumo de redes sociales .
Social Data tiene su sede en Hong Kong y se creó tras la desaparición de otra empresa llamada Deep Social. Esta última empresa parece ser el recopilador original de los datos filtrados. Ambas empresas proporcionan datos demográficos y psicográficos de personas influyentes en las redes sociales a las principales marcas de consumo. Deep Social se cerró en 2018 después de que, según se informa, Facebook le prohibió el uso de sus interfaces de datos de marketing y amenazó con emprender acciones legales. Social Data inició sus operaciones en 2019. Hay muchas otras agencias de “marketing de influencia” (sitio en inglés) que venden este tipo de datos, en caso de que estés interesado en aprender más sobre este rincón del universo de Internet.
Como todos sabemos, los usuarios no pagan para apoyar las plataformas de redes sociales, ganan dinero vendiendo publicidad. Para ser efectivas, las plataformas deben rastrear quién accede a un contenido en particular y todas las plataformas tienen varias interfaces de computadora para permitir a los anunciantes orientar sus anuncios en función de esta actividad.
Pero estas interfaces también pueden ser abusadas, y ese fue el problema con lo que hizo Deep Social . Hay dos formas en que estas agencias pueden operar: una es siguiendo las reglas y obteniendo los datos del usuario de la manera en que Facebook y otros han previsto. La otra es extraer los datos directamente de la página web de cada cuenta y esperar que las empresas de redes sociales no los detecten.
El web scraping ha estado ocurriendo casi desde que se inventó la web a principios de la década de 1990. Es muy probable que alguien haya copiado tu contenido web y lo esté alojando como propio en otro lugar en línea. Lo que ha sucedido es que las herramientas de scraping automatizadas han mejorado para evitar la detección. Cloudflare tiene una explicación más técnica (sitio en inglés) aquí sobre las operaciones de estos "robots scrapers", como se les llama.
Sin embargo, los bots no son perfectos y atrapan a la gente. El ejemplo más destacado es Clearview.ai, que raspó las imágenes de los usuarios y luego comercializó en masa su tecnología de reconocimiento facial (sitio en inglés). Otro caso ocurrió en 2014 con LinkedIn , donde alguien raspó miles de perfiles personales (sitio en inglés) y luego los usó en un sitio que fue creado para sus propios propósitos de reclutamiento.
¿Qué tipo de contenido está disponible para los scrapers? Aquí hay una captura de pantalla de Comparitech que ilustra el nivel de información detallada de la cuenta de Instagram de un usuario.

Crédito: Comparitech
Hay formas de defenderse de los scrapers, dependiendo de si se trata de contenido comercial o personal que estás tratando de proteger. Existen varias herramientas que pueden ayudar a las empresas a detectar cuándo su contenido web se ha retirado y reutilizado en otros lugares, incluidos Cloudflare e Imperva . Pero estos están fuera del alcance para fines personales, y eso significa que debes estar más atento a qué y cómo publicas tus fotos, videos y pensamientos concisos en línea. Deberías pensar en lo siguiente:
1988 - 2026 Copyright © Avast Software s.r.o. | Sitemap Política de Privacidad