
Venez nous rejoindre au Mobile World Congress Americas (MWCA) à San Francisco, où vous pourrez tester notre casque de réalité virtuelle et vous immerger dans le monde du big data.
Vous avez entendu parler du big data... Mais l'avez-vous déjà vu ? C'est désormais possible lors de notre présentation RV à l'occasion du MWCA. Nous mettons notre « espace big data » à la disposition du grand public au MWCA, et ce afin de montrer à tout un chacun comment nous utilisons le big data pour protéger plus de 400 millions d'utilisateurs à travers le monde.
Ces quelques centaines de millions d'utilisateurs se transforment en sources d'informations précieuses qui viennent alimenter notre big data. Si un élément malveillant ou suspect essaie de s'infiltrer dans le système d'un utilisateur, nous en sommes immédiatement informés.
Notre réseau de machine learning basé sur l'intelligence artificielle traite les informations et analyse les dangers potentiels pour mettre en place les mesures nécessaires permettant de mieux s'armer contre ces derniers.
Notre big data vient également enrichir notre « base de données de réputation » d'une envergure sans nulle autre pareille. Lorsque vous accédez à une URL ou exécutez un nouveau programme, la base de données de réputation nous informe du nombre d'utilisateurs y ayant accédé avant vous.
Les programmes et sites Web grand public et sécurisés sont fréquemment visités. Si nous observons qu'une quantité restreinte d'utilisateurs y a accès, c'est peut-être qu'il ne s'agit pas de liens officiels.
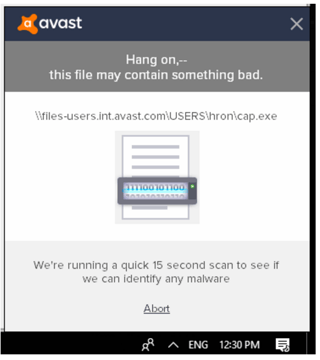
Si vous recevez le message ci-dessus, c'est que nous avons cerné un fichier suspect à l'aide de notre programme CyberCapture. Pour faire simple, nous capturons ce fichier et l'isolons dans un environnement Sandbox.
Si CyberCapture parvient à l'analyser et le considère comme sain, vous pouvez y accéder sereinement. Si, en revanche, CyberCapture estime qu'une analyse approfondie est nécessaire, le fichier est alors envoyé à notre laboratoire de menaces pour une inspection approfondie.
Pour en savoir plus sur la nature des fichiers, nous extrayons un exemple, que nous appelons un « vecteur caractéristique ». Il s'agit d'une coupe transversale comprenant les caractéristiques essentielles du fichier. Nous intégrons ces informations dans notre système de machine learning qui les compare à l'ensemble de notre big data, pour, en fin de compte, les catégoriser comme programmes sains, malveillants ou potentiellement dangereux (LPI).
Plus nous parvenons à enrichir notre big data, plus il est aisé pour nous de comparer les fichiers et programmes douteux avec d'autres données connues.
Nous avons affaire à des millions de fichiers chaque jour ; c'est ainsi que nous avons amassé une base de données considérable. Nous disposons à l'heure actuelle d'environ 330 To de données : une véritable galaxie virtuelle de programmes, qui donne à notre réalité virtuelle les contours d'une voie lactée.
Nos analystes de données plongent dans ce monde virtuel pour inspecter avec rapidité et efficacité nos processus de machine learning et procéder à des vérifications à partir de classifications dédiées. Cet équilibre entre le machine learning et l'intelligence artificielle, conjugué à la perspicacité de nos analystes de menaces, permet à Avast d'offrir une protection contre les menaces, qu'elles soient émergentes ou connues : c'est ce qu'on appelle la cybersécurité nouvelle génération.
Faites un tour au stand Avast au N°658 dans leHall Nord du Moscone Center. Revêtez les lunettes de réalité virtuelle et plongez dans l'univers virtuel des malwares.
Découvrez comment Avast tire parti de l'intelligence artificielle et du machine learning pour protéger plus de 400 millions d'utilisateurs. Nous espérons vous y voir !
Merci d’utiliser Avast Antivirus et de nous recommander à vos amis et votre famille.
1988 - 2026 Copyright © Avast Software s.r.o. | Sitemap Politique de Confidentialité