
L'évolution d'Avast Evo-Gen : Utiliser le machine learning pour protéger des centaines de millions d'utilisateurs
Nous sommes l'une des sociétés leaders en sécurité informatique et nous travaillons assidûment chaque jour pour apporter le niveau le plus élevé de protection à l'ensemble de nos utilisateurs. Cela nous conduit à explorer en permanence de nouveaux moyens de vaincre les malwares, souvent en expérimentant une technologie totalement nouvelle ou des approches qui n'ont jamais été testées auparavant dans notre environnement, et à puiser des idées dans des domaines tels que la biologie ou la physique.
Il est vrai que certaines de ces expérimentations ne donnent rien de substantiel mais il arrive parfois que les résultats dépassent nos attentes, même les plus optimistes. D’ailleurs, nous souhaitions vous parler ici de l'une de ces expérimentations. Nous l'avons lancée il y a plus de six ans et elle a évolué en un système devenu l'un des moteurs de détection des malwares les plus puissants utilisés aujourd'hui par Avast.
Ce système s'appelle Evo-Gen et, si vous suivez notre blog de près, vous en avez peut-être entendu parler dans un article de blog de notre CTO, Ondřej Vlček. En 2012, nous en étions encore à l'époque du premier déploiement de ce nouveau système pour tous les utilisateurs Avast. Ensuite, bien que nous n'ayons plus réellement abordé le sujet dans notre blog, nous avons travaillé dessus ces cinq dernières années, continuant à le contrôler et à l'améliorer en permanence. Si vous entendez parler d'Evo-Gen pour la première fois ou simplement n'en avez pas gardé souvenir, en voici une brève description :
Evo-Gen est un système de machine learning utilisé pour classer des éléments inconnus en temps réel. Pour les éléments reconnus comme malveillants, il crée rapidement une définition qui est immédiatement transmise à tous les utilisateurs Avast pour les protéger de nouvelles menaces.
Les définitions créées (appelées « evogens ») sont très simples et de très petite taille par nature, ce qui signifie qu'elles sont très faciles à évaluer. De plus, chaque evogen protège généralement contre plusieurs menaces car ces définitions sont faites pour être génériques et couvrent donc plusieurs variantes d'une même menace.
Depuis son déploiement en production au début de l’année 2013, Evo-Gen a créé plus de 1,2 million de ces définitions qui identifient près de 500 millions d'éléments malveillants uniques. En faisant le calcul, cela signifie la création chaque jour de 600 evogens et l'identification par chacun d'entre eux de plus de 400 éléments en moyenne ! Les ensembles de données utilisés pour chaque décision ont également considérablement augmenté, passant de quelques millions à plus d'une centaine de millions d'éléments uniques. Et ces chiffres ne prennent pas en compte les centaines d'ensembles en plus que nous utilisons pour les analyses hors ligne et le renseignement contre les menaces. C'est l'acquisition d'AVG en 2016 qui a permis d'enrichir notablement nos ensembles de données grâce à l'apport de dizaines de millions de nouveaux éléments.
Ce qui est extraordinaire est que ce système est entièrement automatisé et qu’aucune interaction humaine n'est requise. Il fonctionne en continu, analyse les éléments entrants et les compare à une énorme collection d'échantillons constituée au fil des années. Toutes les définitions qu'il produit sont quasi instantanément transmises à tous les utilisateurs Avast, par le biais de notre technologie Streaming Update. Ainsi les utilisateurs bénéficient d'une protection de haute qualité en temps opportun.
Dans de rares cas, une définition qui a été transmise doit être désactivée car elle est erronée. Mais quand cela se produit, le système en tire un enseignement et jamais il ne refera la même erreur. De tous les evogens créés à ce jour, plus de 40 % sont encore actifs et utilisés chaque jour. Quelques-uns d'entre eux sont de véritables champions, ayant identifié non pas des centaines mais des millions d'éléments uniques.
Comme je l'ai mentionné au début de cet article, le système dans son ensemble a subi un tas de changements depuis son déploiement au début de l’année 2013. Il a évolué d'une petite preuve de concept avec des définitions de courte durée en un moteur de détection de malwares stable et de haute qualité. C'est encore plus évident si vous regardez le graphique agrégé ci-dessous qui montre que, par le passé, nous avons dû désactiver bien plus d'evogens que de nos jours :
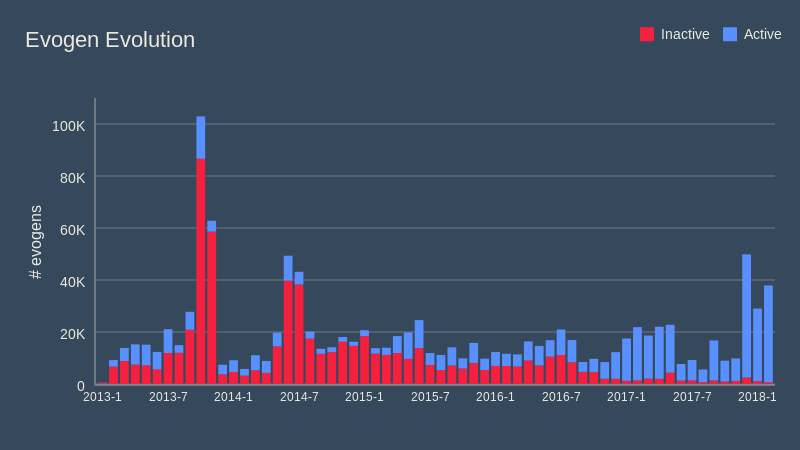
Vous remarquerez le grand pic du nombre de définitions créées au cours de l'été 2013. À cette époque, nous voulions qu'Evo-Gen produise plus de définitions génériques de façon à couvrir un éventail de menaces le plus étendu possible. Dans ce but, nous avons augmenté l'amplitude aléatoire que le générateur de définitions était autorisé à utiliser. Quelques mois plus tard cependant, ce changement a dû être inversé car il s'est avéré trop agressif et nous sommes revenus à une approche plus déterministe.
Il était intéressant de voir comment, dans nos tests internes, nous n'avions aucun problème en ajoutant plus d'amplitude aléatoire, mais que l'incroyable variété des échantillons provenant du monde externe conduisait notre système à produire trop de définitions avec des faux positifs dans certains cas particuliers. La mise au jour de ce problème dans un environnement de labo n'était simplement pas possible et nous avons appris la leçon à nos dépens.
Pendant l'année 2014, nous nous sommes principalement consacrés à la stabilisation du système, à la résolution des bogues et des cas particuliers ici et là. Puis en 2015, nous avons commencé à envisager une réécriture majeure de l'algorithme du générateur. Jusqu'alors notre approche n'exploitait pas réellement le plein potentiel de la base de données sous-jacente, autrement dit, la recherche de similarité qui était utilisée très naïvement pour exécuter une recherche k-NN avec quelques contraintes spécifiques de domaine et des règles issues des connaissances des experts.
Après quelques recherches, nous avons conclu que l'utilisation de HDBSCAN (une variante de https://en.wikipedia.org/wiki/DBSCAN) était la meilleure option et nos tests préliminaires étaient pleins de promesses. Cependant, développer une variante qui fonctionnait bien dans les contraintes de temps que nous avions (souvenez-vous que le système est supposé créer une définition en temps réel) s'est révélé un vrai défi et il s'est passé plus d'une année avant de parvenir à la mettre en production. Cela s'est produit fin 2016 et le succès était au rendez-vous. Dans les quelques mois qui ont suivi le déploiement, nous avons constaté une diminution spectaculaire du nombre d'evogens désactivés, qu'il s'agisse de faux positifs internes ou externes. En 2017, nous avons apporté des ajustements mineurs à l'algorithme et amélioré la performance des bases de données sous-jacentes, ce qui les a rendues encore plus performantes.
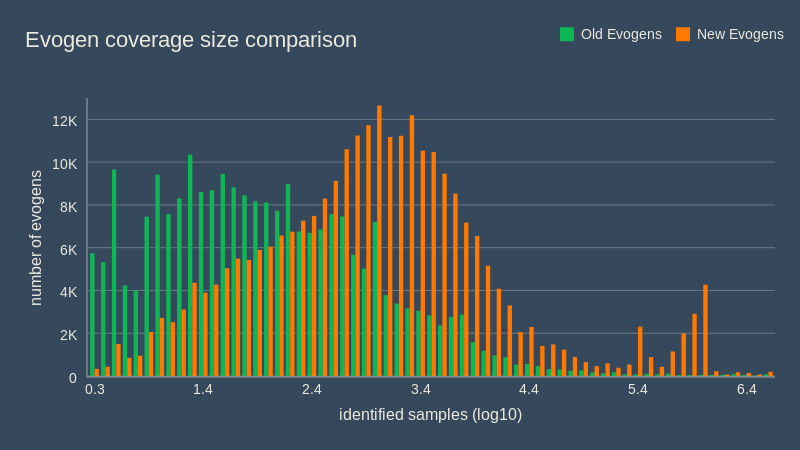
Le diagramme ci-dessous compare l'ancien et le nouveau générateur de définitions uniquement du point de vue de la couverture des éléments définis, c'est-à-dire la quantité d'échantillons uniques que chaque définition est capable d'identifier. Vous pouvez voir que l'ancienne version générait des evogens dont la couverture était réduite comparée à la nouvelle. Combinée avec le taux beaucoup plus bas d'evogens désactivés, l'augmentation des éléments détectés était visiblement considérable. Evo-Gen était devenu l'un des moteurs de détection les plus puissants, battant les systèmes en place à la fois en qualité et en vitesse.
Bien évidemment, nous n'allons pas en rester là, nous n’allons pas nous arrêter en si bon chemin. Mais voyons d'abord ce qui fait la puissance d'Evo-Gen :
C'est grâce aux caractéristiques ci-dessus que le machine learning est si utile. Il est également plus facile à proportionner qu'une équipe humaine car si vous pouvez facilement acquérir une paire de serveurs supplémentaires, il est beaucoup plus difficile d'engager plusieurs analystes de programmes malveillants compétents.
Toutefois, il existe un inconvénient. Comme les menaces doivent être neutralisées avant qu'elles ne soient parfaitement comprises et schématisées, les evogens individuels ne peuvent pas être affinés à la perfection car ils doivent être publiés aussi vite que possible. Au final, cela conduit le système à créer plusieurs evogens pour une seule famille de malwares et même, dans certains cas, pour des centaines. Le graphique qui suit illustre la façon dont la redondance apparaît.
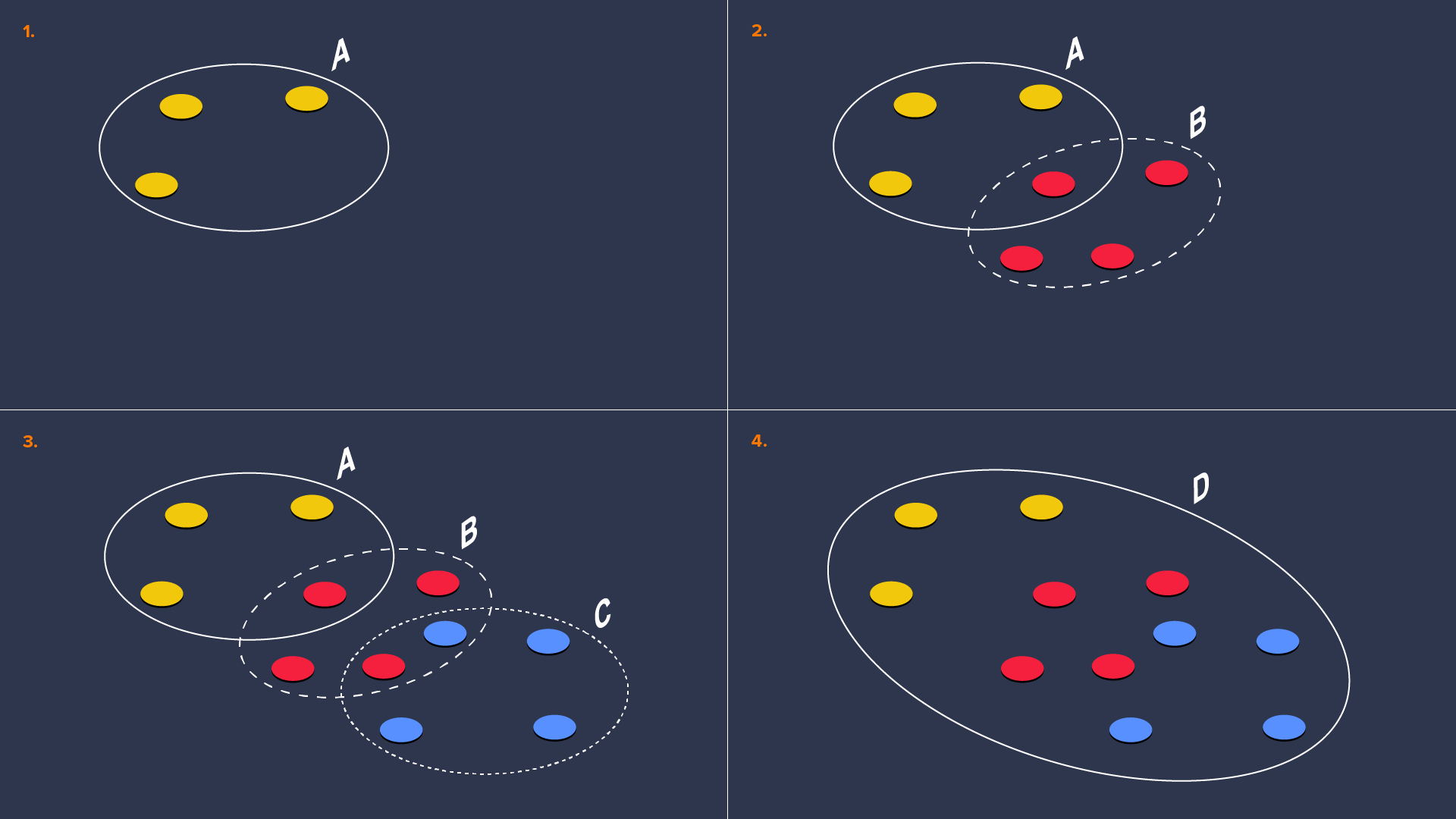
Dans la première image ci-dessus, les trois cercles jaunes représentent quelques variantes (échantillons) d'une seule famille de malwares. Elles sont contenues dans un anneau gris qui représente une définition (evogen A) capable de les identifier. Cependant, plus tard émergent plusieurs variantes (rouges) et si certaines sont encore identifiées par l'evogen A, d'autres restent non identifiées. Par conséquent, l'evogen B est créé pour s'en charger. Ce phénomène se répète dans la troisième image avec des variantes en bleu et l'evogen C. La dernière image illustre la situation idéale où une seule définition, l'evogen D, est capable de prendre en charge toutes les variantes.
Si toutes les variantes émergeaient au préalable, il serait certainement possible de créer un seul ou quelques evogens qui les couvriraient toutes. Cela faciliterait grandement la détection des menaces, car moins il y aurait de définitions, moins de temps serait nécessaire et les mises à jour seraient moins importantes.
Malheureusement, cela n'est pas réalisable en pratique, puisqu'il faut attendre l'apparition de plus d'échantillons et que les premiers peuvent alors se propager. Pour nous, cette impossibilité n'est pas acceptable. Cette redondance peut heureusement être résolue plus tard, en s'attaquant à un problème bien connu appelé le « problème de couverture par ensembles ». Dans ce problème, nous avons un ensemble d'éléments (dans le cas présent, les échantillons de malware) et une collection d'ensembles (les evogens) dont la somme est égale à tous les éléments. Le but est d'identifier la sous-collection la plus petite d'ensembles (evogens) dont la somme est encore égale à tous les éléments. C'est un problème NP-complet mais, heureusement pour nous, nous n'avons pas besoin d'une solution parfaite mais juste d'une solution correcte. Nous avons conçu un outil qui fait exactement cela et, après lui avoir chargé toutes les données (plus d'un demi-million d'evogens et près de 500 millions d'éléments, nous avons obtenu le résultat suivant :
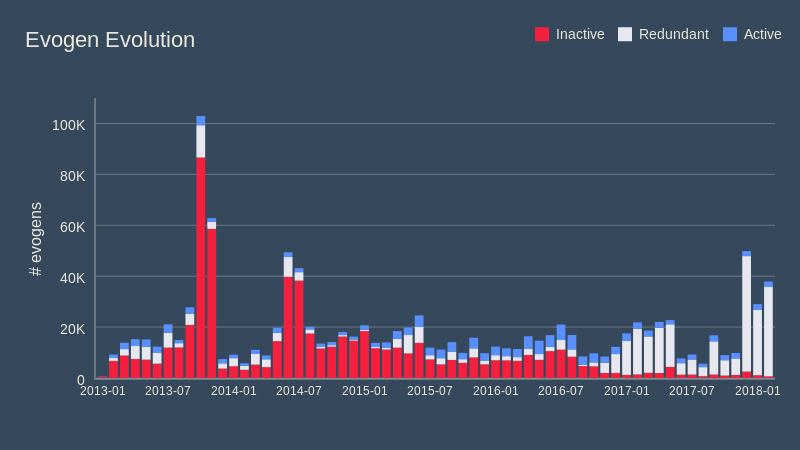
Près de 60% des evogens ont été marqués comme redondants, ce qui signifie que nous pouvons les supprimer en toute sécurité avec pour résultat une optimisation massive ! Il est clair que, en pratique, nous serons un peu moins extrémistes, juste par sécurité, mais cela nous montre que nous pouvons réduire significativement le nombre de définitions sans aucun impact sur nos capacités de protection. Moins de définitions signifie des analyses plus rapides et des mises à jour moins importantes, donc un gain pour l'utilisateur aussi.
Vous avez peut être remarqué que la redondance semble être apparue plus récemment, mais c'est seulement vrai en partie. La redondance a toujours été présente mais, antérieurement, nous avions plus de mauvais evogens et donc beaucoup d'evogens redondants ont déjà été désactivés et sont « masqués » (inclus dans la barre rouge). De plus, le nouvel algorithme déployé fin 2016 fait de meilleures prédictions concernant le groupe de vraies menaces, mais il examine la menace depuis de nombreux angles différents (en fonction de l'élément qu'il analyse) ce qui conduit à un remplacement excepté celui des evogens corrects. L'ancien algorithme ne possédait pas cette fonctionnalité car il était un peu trop aléatoire ou trop déterministe.
Chez Avast, notre mission est de maintenir la sécurité de nos utilisateurs en ligne et nous sommes toujours à la recherche de nouveaux moyens de les protéger. Evo-gen est un bon exemple de technologie dont le développement a pris beaucoup de temps, mais qui au final s’est révélé payante ; elle a permis d'augmenter le niveau de protection que nous offrons à nos utilisateurs. Nous explorons en permanence de nouvelles opportunités qui optimisent la protection d'Avast et de ses utilisateurs contre les logiciels malveillants et leur monde en perpétuel évolution.
Merci d’utiliser Avast Antivirus et de nous recommander à vos amis et votre famille. Pour connaître les dernières actualités, pensez à nous suivre sur Facebook, Twitter et Google+.
1988 - 2026 Copyright © Avast Software s.r.o. | Sitemap Politique de Confidentialité